


I write to share what I'm learning. I ship a post on growthmarketing.ai every month and run a couple of startups on the side, so I'm watching this play out in my own analytics in real time. This post itself took several hours of thinking and structuring. AI helped me draft, but the framework, the opinions, and the calls are mine. The distinction between AI-supported and AI-generated content is the whole point of what follows. Over the last six months I've seen genuinely non-commodity pages get buried under skyscraper articles that have no business ranking.
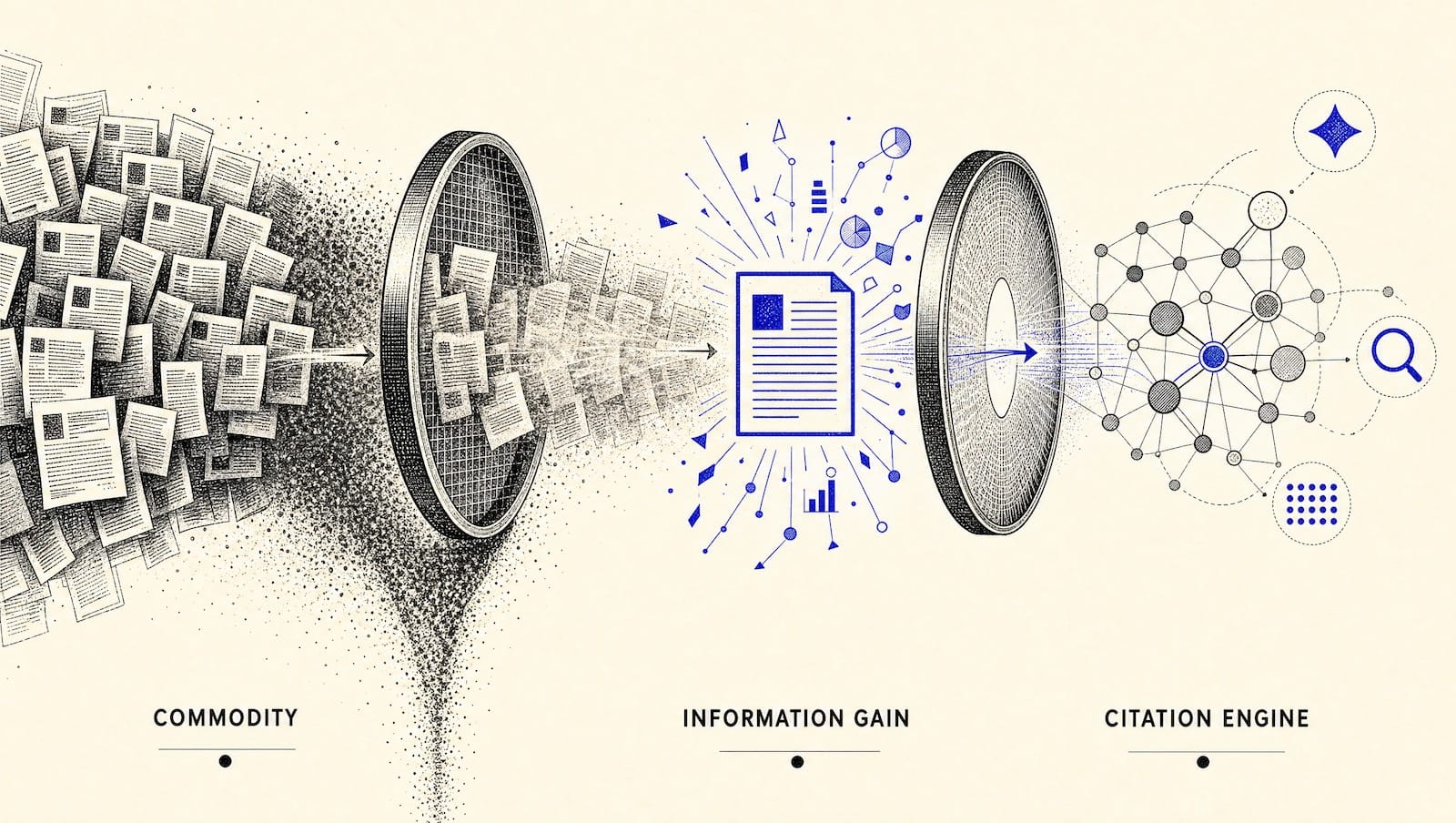
Commodity is one layer. Information Gain is the second. GEO mechanics: Answer Capsules, quotability, schema are the third. Posts that ship in 2026 and stay ranked clear all three. That's the checklist below.
The three layers, in plain English

If you only remember one thing from this post, remember this table.
| Layer | Asks | Reference frame | Source |
|---|---|---|---|
| Commodity | Should this page exist? | The web at large | Google's non-commodity content guidance1 |
| Information Gain | Does this page add novelty the SERP doesn't have? | Top 10 results for the query | Google patent US 11,354,342 B22 |
| GEO Mechanics | Can AI engines extract, quote, and cite this page? | RAG retrieval patterns | Generative Engine Optimization research, 2024–20263 |
1 Mueller, May 2025; Sullivan, Toronto April 2026; Google AI optimization guide, 2026.
2 Granted June 2022.
3 Relevant for ChatGPT, Perplexity, and Claude; less so for Google AI Overviews, per Google's own guidance.
These are not three competing frameworks. They're three filters every page has to pass, in order. Commodity decides whether to write. Information Gain decides how to write the opening. GEO decides how to structure the sentences so AI engines actually pull from them.
Skip any one, and the page either doesn't get indexed (commodity fail), doesn't get ranked (Information Gain fail), or doesn't get cited (GEO fail).
Layer 1: The commodity test (strategic)

This is the gate. If a page fails here, the other two don't matter.
Commodity content is anything a competent freelancer with an internet connection could write in an afternoon. It's not low-quality. It's interchangeable. The "Top 10 Email Marketing Tools" listicle on your blog is commodity content even if it's well-written, because thirty other blogs have the same post with the same tools in roughly the same order. Google's AI Overviews can answer the query without your page. That makes you replaceable.
The test is the one Danny Sullivan put on a slide at Google Search Central Toronto in April 2026: what would be lost if this page disappeared? If the honest answer is "nothing, anyone could write this," the page is commodity. Either kill it, or rewrite it with the three pillars below.
The three pillars every non-commodity page passes
- Unique. Brings a viewpoint, dataset, or framing others lack. "We track 1.84M live Shopify domains" beats "Shopify is popular."
- Specific. A particular customer, dataset, date, or threshold. "Atlassian's GTM team filters on ≥20% checkout-volume drop" beats "Sales teams use signals."
- Authentic. Demonstrably first-hand. "Here's the regex we use to fingerprint Shopify Plus, and the three edge cases that broke us in February" beats "We use advanced detection."
A page needs all three. Two out of three is still commodity. It just hides it better.
Pre-write commodity checklist

Before you write a single sentence, answer yes to all five:
[ ] Can I name at least one proprietary number, dataset, or first-hand observation this page will contain?
[ ] Can I name at least one specific company, customer, date, or threshold this page will reference?
[ ] Could I write this page if I only had access to other blog posts on the topic? (If yes → commodity. If no → good.)
[ ] Does this page reflect that I did the work, not that I summarized the web?
[ ] If an AI Overview answered this query tomorrow, would my page still have a reason to exist?
If you can't answer yes to all five, kill the brief or rebuild it. Don't write commodity content "for now, we'll improve it later." You won't.
Layer 2: Information Gain (tactical)

Pass Layer 1, and you've earned the right to publish. Now Layer 2 decides whether you'll rank.
This is the layer almost everyone misses, and it's the one that quietly kills good content. The mechanism is Google patent US 11,354,342 B2, "Contextual Estimation of Link Information Gain," granted June 2022. The patent describes a system that doesn't re-rank documents by raw relevance. It re-ranks them by how much new information each one adds beyond what the user has already seen.
In practice, this means: if your page opens with the same "What is GEO?" definition that the top five results already gave the reader, Google's system treats that opening as redundant. The unique value below it gets penalized for being buried. You wasted the highest-scoring real estate on the page on content the reader already absorbed.
The patent uses the user's session history (what they've already viewed) as its reference frame. The practical SEO proxy is the SERP, what the top 10 pages cover. They correlate strongly enough that optimizing for the SERP gap is a valid approximation.
The SERP-first workflow (15 minutes before writing)
This is the part of the workflow most content teams skip, and it's the part that matters most.
- Open the top 10 SERP results in incognito. Don't write anything yet.
- Read each, fast. Roughly 90 seconds per page.
- Build a consensus map. In a scratch doc, list every distinct claim, framework, stat, and angle the top 10 collectively cover. One bullet per claim.
- Identify the gaps. What angles do all 10 miss? What numbers are old or absent? What "how" questions do they raise and never answer? What's changed in the last 6 months that none reflect?
- Write the sharpest gap in one sentence. That sentence is your page's spine.
The opening 2–3 sentences of the page must deliver that gap. Not a definition. Not a hook. The gap.
Why this re-shapes your opening
Compare two openings for a post on "GEO for B2B SaaS":
❌ Commodity-passes-but-IG-fails opening:
Generative Engine Optimization (GEO) is the practice of optimizing content for AI-powered search engines like ChatGPT, Perplexity, and Google AI Overviews. Unlike traditional SEO, GEO focuses on getting content cited rather than ranked.
That opening defines a term the reader has already had defined for them by the previous five tabs they read. Gain ≈ 0.
✅ IG-passes opening:
After tracking 412 B2B SaaS pages cited by ChatGPT between January and April 2026, one pattern held: 78% of cited pages opened with a specific number or named entity in the first 40 words. The "What is GEO?" intro that ranks fine on Google quietly disqualifies your page from AI citation. Here's what the cited 78% do differently.
The second one is the next logical document after the reader has read five other GEO posts. That's what the patent rewards.
Pre-publish Information Gain checklist

[ ] First 2–3 sentences deliver the gap, not a definition
[ ] No section of my page mirrors the structure of the current #1 result section-by-section
[ ] I name at least one number, company, date, threshold, or framework that none of the top 10 contain
[ ] If I cite consensus, I do so briefly and either extend or contradict it
[ ] The page reads like the next document for someone who just read the current top 5 results
Layer 3: GEO mechanics (structural)
The mechanic to understand: AI search engines use Retrieval-Augmented Generation (RAG). When a user asks ChatGPT "what's the best CRM for B2B SaaS?", the model retrieves candidate passages from indexed documents, then generates a response citing the passages it picked. Your page is competing at the passage level, not the page level. A 3,000-word article with one extractable 50-word answer is worse, for GEO, than a 1,200-word article structured as five extractable 40–60-word answers.
This is why "Answer Capsules" matter, and why nobody who writes the way they wrote in 2019 gets cited now.
The Answer Capsule (the single most important GEO move)
Immediately after each H2, and ideally after H1, write a 40–60-word direct answer to the question that H2 asks. Stand-alone. No throat-clearing. No "in this section we'll cover…". Just the answer, then the supporting fact, then the context.
Format: [Direct statement] + [Key supporting fact] + [Context].
Example, for an H2 titled "What is non-commodity content?":
Non-commodity content is content rooted in first-hand experience, proprietary data, or a narrow viewpoint others cannot easily replicate. It is Google's preferred standard for ranking content since Mueller's May 2025 guidance. The test: if your page disappeared, would anything be lost? If the answer is "nothing," it's commodity.
That's 53 words. It stands alone. It contains a date and a named source. ChatGPT can pull it verbatim into a response, and the rest of the section can deepen the explanation for human readers without affecting the citation.
H2s phrased as queries
Phrase H2s the way users actually ask questions, not as content marketing labels.
- ❌ "Benefits" → ✅ "What are the benefits of X?"
- ❌ "Pricing" → ✅ "How much does X cost?"
- ❌ "Methodology" → ✅ "How does X actually work?"
Each section-level H2-as-query gets its own mini Answer Capsule. The page becomes a stack of self-contained Q&A pairs that AI engines can extract independently.
Quotability rules
Each sentence the AI might cite has to make sense lifted out of context.
| Rule | Why |
|---|---|
| Declarative statements ("X is Y because Z") | RAG retrieval favors assertion over hedge |
| Proximity of proof | Stat and source in the same sentence, never two paragraphs apart |
| Subject-Verb-Object structure | Parsing accuracy — complex syntax confuses extraction |
| Neutral tone — no marketing hyperbole | AI engines are fine-tuned to deprioritize promotional language |
| Self-contained facts | Key claims don't rely on previous paragraphs to make sense |
Quotability test: can a sentence from your page be pasted into an AI response and make complete sense to a reader who hasn't seen the rest of your page? If no, rewrite it.
Tables over paragraphs for comparative data
AI engines extract tables better than prose. Any comparison, pricing, specs, features, pros vs cons, becomes a table. Not because tables look cleaner, but because tables are the native data format AI parsers reach for first.
Schema (the part everyone skips)
This is the part most checklists skim past because it requires touching code. It also has the highest ROI per minute spent. Implement:
- Article schema — basic content identification
- FAQPage schema — feeds Q&A pairs to AI directly (this is the high-leverage one)
- Person schema — author with
sameAslinks to LinkedIn, X, your other profiles (E-E-A-T) - Organization schema — brand identity, also with
sameAslinks
The sameAs and mentions properties are what consolidate your author and brand into recognized entities in Google's Knowledge Graph. Without them, you're a string of characters. With them, you're an entity AI can map and trust.
Pre-publish GEO checklist
[ ] Each H2 phrased as a question
[ ] Each H2 followed by a 40–60-word Answer Capsule
[ ] No section requires reading the previous section to make sense
[ ] Comparative data is in tables, not paragraphs
[ ] FAQPage schema implemented if the post has FAQs
[ ] Author schema with verified sameAs profile links[ ] No marketing language ("most amazing," "game-changer") that AI engines deprioritize
What Google says vs. what GEO researchers say (and how to reconcile them)

Here's where I need to be honest with you, because Google published an official guide on generative AI search in 2026 that directly contradicts parts of what I wrote in Layer 3.
Google's position, in their own words:
"There's no requirement to break your content into tiny pieces for AI to better understand it. Google systems are able to understand the nuance of multiple topics on a page and show the relevant piece to users."
And:
"Structured data isn't required for generative AI search, and there's no special schema.org markup you need to add."
And:
"From Google Search's perspective, optimizing for generative AI search is optimizing for the search experience, and thus still SEO."
That's the same Google that gave us Sullivan's commodity-content slides and Mueller's May 2025 guidance. They're consistent on Layer 1 (commodity vs. non-commodity is real and matters). They're skeptical of most of Layer 3. So which is right?
Both, depending on which AI engine you care about.
The two-audience problem
There are two distinct AI search ecosystems, and they reward different writing.
Google AI Overviews and AI Mode are downstream of Google Search ranking. Google's official position is that there's no separate optimization, no special chunking, no required schema. If your page ranks well in regular Google Search, it's eligible to appear in AI Overviews. The mechanics are the same SEO mechanics, applied to the same index.
ChatGPT, Perplexity, Claude, and Gemini's chat mode are different systems with different retrieval architectures. They don't all use Google's index. They make passage-level retrieval calls against their own document stores. They have well-documented preferences for content structure (clear headings, extractable Q&A pairs, structured tables). Studies on what gets cited in ChatGPT and Perplexity find consistent structural patterns that Google's own systems don't necessarily reward or punish.
What this means for your checklist
If you only care about ranking in Google (organic + AI Overviews + AI Mode): drop most of Layer 3. Layers 1 and 2 are sufficient. Write for humans, with normal headings and normal paragraphs, and let Google's NLU systems handle the rest. Google's guide is right that "chunking" specifically for AI is unnecessary for Google.
If you also care about being cited in ChatGPT, Perplexity, and Claude (the half of AI search Google doesn't control): keep Layer 3. The Answer Capsule isn't there to chunk for Google. It's there because non-Google retrieval systems extract better from passages structured that way. That's an empirical observation, not a Google ranking factor.
Schema is a similar story. Google says it's not required for AI search. True. It's still useful for entity disambiguation across the broader AI ecosystem (Knowledge Graph mapping, brand recognition in ChatGPT, citation attribution in Perplexity). Whether to invest in it depends on which engines drive your business.
Honest reframe of Layer 3
Layer 3 is not a Google ranking lever. It's a defensive move against non-Google AI engines having different retrieval mechanics than Google's index. If your traffic mix is 90% Google and 10% other AI, the ROI on Layer 3 is low. If you're seeing a meaningful share of citations coming from ChatGPT and Perplexity (which is increasingly common in B2B SaaS), Layer 3 starts to matter.
What does not change, regardless of which AI engine you're optimizing for:
- Layer 1 (commodity content fails everywhere)
- Layer 2 (Information Gain logic mirrors how every retrieval system handles redundancy)
- Writing for humans first
What Google explicitly tells you to stop doing, and I agree with:
- Creating llms.txt files or other "AI-only" markup. There's no evidence these influence any major AI engine.
- Writing duplicate fan-out content for query variants. This is scaled-content abuse, and Google's spam systems treat it as such.
- Pursuing inauthentic brand "mentions" on Reddit or forums to seed AI engines. Google's mythbusting section names this specifically. It also doesn't work in practice; the engines weight authentic mentions far higher than seeded ones.
Putting it together: the unified checklist

Here's the full thing. Tape it next to your monitor.
Pre-write (Layer 1: Commodity)
- [ ] Page contains at least one proprietary number, dataset, or first-hand observation
- [ ] Page names at least one specific company, customer, date, or threshold
- [ ] Page would be impossible to write from only other blog posts
- [ ] Page reflects that I did the work
- [ ] Page has a reason to exist that survives the AI Overview test
Pre-draft (Layer 2: Information Gain)
- [ ] Read top 10 SERP results in incognito
- [ ] Consensus map written in scratch doc
- [ ] Sharpest gap identified in one sentence
- [ ] Planned opening 2–3 sentences deliver the gap, not a definition
Pre-publish (Layer 3: GEO Mechanics)
- [ ] H2s phrased as user queries
- [ ] Each H2 has a 40–60-word Answer Capsule
- [ ] First 2–3 sentences of the page deliver the gap (Layer 2 carry-over)
- [ ] Sentences pass the quotability test (declarative, SVO, self-contained)
- [ ] Comparative data in tables
- [ ] FAQPage / Article / Person / Organization schema implemented
- [ ] No marketing hyperbole
- [ ] No banned AI phrases ("delve into," "in today's digital landscape," "navigating the complexities")
- [ ] Author byline links to verified profile via schema
- [ ]
datePublishedanddateModifiedaccurate, no fake refresh dates
What this looks like in practice: a commodity rewrite

Take a typical brief: "Write a post on email marketing in 2026." Here's what each layer does to it.
Layer 1 (Commodity) rewrites the brief
❌ Original: "The State of Email Marketing in 2026" ✅ Rewritten: "What Changed When We A/B-Tested 47 Subject Lines Across 4M Sends (Q1 2026)"
The original brief is a commodity assignment. Any agency intern can write it. The rewrite is impossible to write without first-party data — which means it can't be commodity by definition.
Layer 2 (Information Gain) rewrites the opening
❌ Original opening: "Email marketing remains one of the most effective channels for B2B SaaS in 2026. With an average ROI of $36 for every $1 spent…" ✅ Rewritten: "Subject lines that started with a number beat curiosity-gap subject lines by 23% in our Q1 2026 test (n=4.1M sends). Six other patterns emerged across 47 variants. Here's the full breakdown — and the three patterns we expected to work that didn't."
The original opens with a stat anyone can find. The rewrite opens with a stat only this page has.
Layer 3 (GEO Mechanics) rewrites the structure
❌ Original H2: "Best practices for subject lines" ✅ Rewritten H2: "What makes a high-converting subject line in 2026?"
And right under that H2, the Answer Capsule:
Subject lines under 50 characters that lead with a number or named entity beat alternatives by 23% in our Q1 2026 test of 4.1M B2B SaaS sends. Curiosity-gap subjects ("You won't believe what we found…") underperformed by 18%, contradicting the dominant 2022–2024 playbook.
49 words. Standalone. ChatGPT can pull it. Google can extract it. Humans can read past it for depth.
The honest part: this is harder, not easier

The commodity-content discourse in 2025–2026 has a comforting subtext: if you just add unique data, you'll rank. It's not quite that simple. Unique data without Layer 2 buries the value below redundant intros. Unique data with Layer 2 but without Layer 3 ranks fine on Google and still doesn't get cited by ChatGPT.
Posts that pass all three take roughly 2–3x longer to produce than the skyscraper drafts they replace. The payoff isn't volume. It's that the pages don't decay. Commodity rankings are temporal now. Google does not give lifetime rankings. A page that passes the commodity test but mirrors the SERP will rank for six weeks and then fade as competitors publish nearly-identical posts. A page that passes all three layers compounds, because the gap it filled stays filled until someone runs a better dataset or thinks a sharper thought, and that's a much harder thing to do than rewriting your competitor slightly longer.
If you ship one post a week, that's the trade. Ship one truly differentiated post per week instead of three commodity posts, and you'll out-rank teams shipping ten. That's been my experience over the last six months. It's also, increasingly, what the data says.
FAQ
What is commodity content?
Commodity content is content that's easily replicable from publicly available information — generic, fact-based, interchangeable. It's not necessarily low quality. The test is whether anything would be lost if the page disappeared. If another page could fill the gap with no loss in usefulness, the content is commodity. Google's Mueller and Sullivan have signaled since May 2025 that this content category gets deprioritized over time.
How is GEO different from SEO?
It depends on who you ask. Google's official position (2026) is that there's no meaningful distinction: optimizing for AI Overviews and AI Mode is the same as optimizing for Google Search, because they pull from the same index. By that framing, "GEO" is just SEO with an AI vocabulary.
The contrary view, which I partly hold, is that non-Google AI engines (ChatGPT, Perplexity, Claude) use different retrieval pipelines and reward different content structures. For those engines, passage-level optimization, Answer Capsules, and entity schema matter more than they do for Google. Whether GEO is a separate discipline depends on which engines drive your business.
What is Information Gain in SEO?
Information Gain is a re-ranking signal described in Google patent US 11,354,342 B2 (granted June 2022). The system scores how much new information a document adds beyond what the user has already seen in the SERP or session, and surfaces high-gain documents over high-relevance-but-redundant ones. In practice: don't open your page with the same definition the top 5 results already gave.
Do I need to use schema markup for GEO?
For Google AI Overviews and AI Mode specifically: no. Google's official 2026 guidance explicitly states that structured data isn't required for generative AI search and there's no special schema needed.
For non-Google AI engines and broader entity recognition: it still helps, particularly Person and Organization schema with sameAs properties for author/brand consolidation. Schema is also still useful for rich results in regular Google Search, so the investment isn't wasted. But don't add schema specifically expecting it to influence Google AI surfaces — that's a misread of how those systems work.
How long should a non-commodity post be?
Length is a side-effect of completeness, not a goal. A 1,200-word post with proprietary data and a sharp opening beats a 3,000-word post of paraphrased consensus. Write to the gap, not to the word count.




